Insiders LLM Benchmarking September 2025

The Insiders LLM Benchmarking in September 2025 continues the series and builds consistently on the findings from Q2. To ensure comparability, identical dimensions and test data are used as in the previous benchmarking.
The market for large language models (LLMs) is developing rapidly. New models appear on a monthly basis, existing ones are further optimized—and not all of them prove themselves in practice. With the current Insiders LLM Benchmarking for Q3 2025, we create transparency and provide companies with sound guidance: Which models deliver the best quality? What are the limitations in productive use? And how can performance and security be reconciled?
A practical comparison
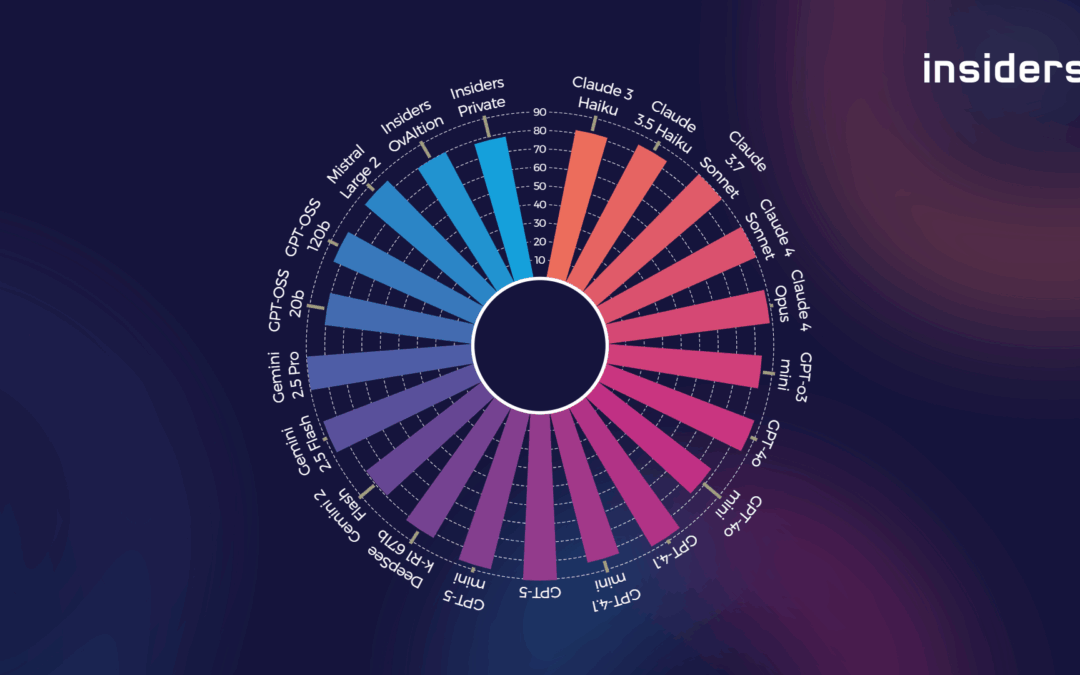
As in Q2, we tested the leading models based on a standardized IDP dataset – real documents from insurance and finance. This ensures that the results are directly transferable to our customers‘ requirements. The benchmarking covers a total of 21 models, including new additions such as GPT‑5, Gemini 2.5 Pro, and Claude 4 Sonnet.
The comparison shows that global models set the benchmark thanks to their huge databases and computing resources. However, in regulated industries in particular, data protection, transparency, and integration capabilities are just as crucial as pure performance.
By switching to a more powerful model, Insiders Private was able to achieve a significant leap in quality: from a score of 67.9 in Q2 to 78.2 now – while maintaining the same average processing time per document. This brings it closer to the top models without compromising on data protection or speed.
The current Insiders LLM benchmarking illustrates that Insiders continuously monitors the market and masters the balancing act between performance and security for its customers – with a clear best-of-breed approach. This approach means that no single model covers all tasks, but rather that the most powerful LLMs are identified, evaluated, and flexibly integrated for each application. New models are therefore immediately tested in benchmarking and compared with existing ones. The results flow directly into product development and ensure consistently high quality.
The question of “the best LLM” is not a black-and-white issue. Performance alone is not enough. In highly regulated industries such as insurance and finance, reliability, data protection, and integration capabilities are also key factors.
For individual use cases, Insiders AI experts offer sound advice for your company. We would be happy to include your data in an upcoming industry-specific benchmarking exercise. Simply contact our Insiders AI experts to find out more.